


Our Philosophy
Our work is rooted in an enduring belief that thoughtful and systematic analyses of available data, coupled with a sound understanding of industry dynamics and trends give rise to informational advantage, which in turn precipitates measurable gains in the efficacy of business decisions.
With that in mind, we make it our mission to analyze emerging industry trends and key developments, continuously amass risk event data, leverage already-proven and emerging data analysis and visualization approaches and tools, all as means of developing valid and reliable mechanisms for estimating company-specific exposures to adverse developments.
Our Approach
Multisource and multivariate are the two key characteristics of our approach: The former reflects our emphasis on simultaneously analyzing source-dissimilar but outcome-related data types; the latter underscores our commitment to pursuing maximum amounts of knowledge that might be hidden in data.
In keeping with that mindset, our data analytic approach follows a simple, three step process: data -> information -> knowledge, which ultimately enables us to distil the commonly large volume of technical findings into a more manageable set of practically relevant decision drivers, offering clear and meaningful decision guidance.
Select Data Analytic Approach Highlights
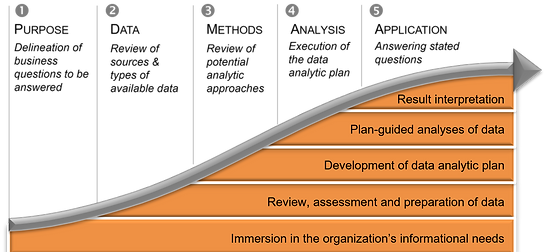
Informational Need-Driven Insight Discovery
Our research and analysis is guided by the following tenets: 1. manifest informational needs should be the starting point of business analytics, 2. the ensuing analyses should be built around valid and reliable transformations of raw, multi-source data into decision-guiding insights, and 3. the resultant decision-guided knowledge should be communicated in the manner that is easily understood by users, and the efficacy of data analysis-derived insights should be assessed on ongoing basis.
Amalgamation of Multi-Sourced Input Data
It is our belief that the essence of data analytics is to use all available data and to systematically and reliably transform those data into maximally informative decision-guiding knowledge. This conviction is particularly visible in our SCA Risk Tracker informational reservoir, which combines otherwise standalone securities litigation filings, securities litigation settlements, daily stock price volatility, annual SEC filings, and a cross-section of firmographics into company-specific, industry- and size-adjusted securities litigation likelihood and severity estimates.

Systematic & Thoughtful Data Analytic Processes
We view analytic findings as the beginning, not the end of the data mining process - although we are cognizant of the value of analytic outcome summarizing reporting, our ultimate goal is to turn generic informational outcomes into unique, decision-guiding, competitively advantageous insights. We believe that while basic reporting can yield worthwhile 'what-is' information, it is the more involved deeper dive analytics that offer decision uncertainty reducing 'why' and 'what's next' knowledge.
Ongoing & Standardized Insights
To be a source of ongoing organizational value, data analytic insights need to track events or developments of interest, as exemplified by our SCA Tracker system. Moreover, those insights need to be comparable across time and across entities, to support longitudinal tracking and peer benchmarking, respectively, comparisons.
